
OCR - Data Capture
Paper documents are scanned in a multi-step process: first, a digital image is generated with a scanner. This is followed by more complex operations of data extraction and document classification. Powerful OCR (Optical Character Recognition) software recognises content automatically.
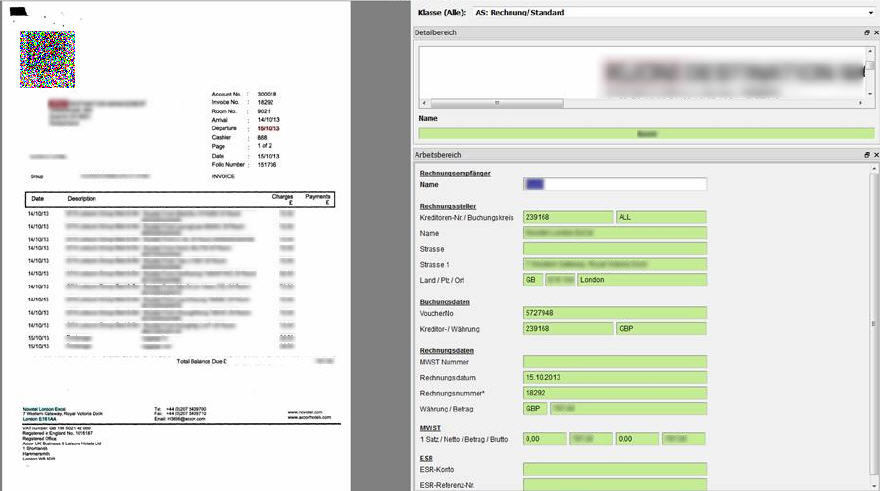
OCR data extraction: how documents are converted into information
This is a very reliable process with a high recognition rate when the quality of the printed text is high. Lower-quality documents and handwriting often push automatic processes to their limits. Results are improved by means of comparison with existing master data (personnel, creditors, orders, etc.).
Index data can be automatically recorded, validated and tested in a variety of ways. Content that is not recognised or is not clear in the scan is manually added or corrected accordingly. Data and images (PDF, TIFF, etc.) processed in this way is then exported into the workflow.
