
Rejestracja danych (OCR)
Proces skanowania papierowych dokumentów odbywa się w kilku krokach. Najpierw za pomocą skanera uzyskuje się cyfrowy obraz, a następnie wykonuje się bardziej zaawansowane czynności: klasyfikację dokumentów oraz ekstrakcję danych. Dzięki wydajnemu oprogramowaniu OCR (ang. optical character recognition) treść zostaje automatycznie rozpoznana.
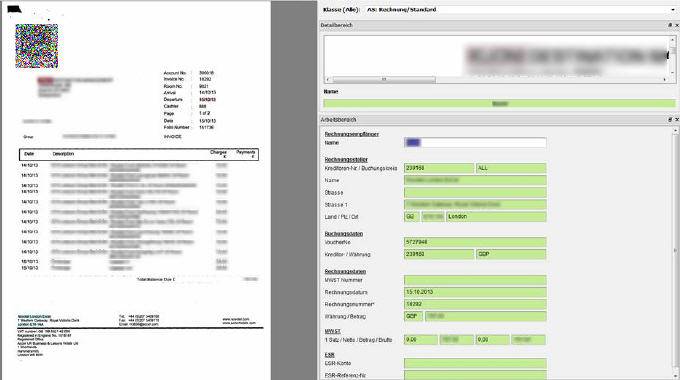
W jaki sposób dokumenty są przetwarzane na informacje: ekstrakcja danych OCR
W przypadku tekstów o dobrej jakości druku udaje się uzyskać wysoki współczynnik rozpoznania zapewniający duży poziom niezawodności, a w przypadku niższej jakości dokumentów oraz pisma ręcznego możliwości zastosowania automatycznego przetwarzania są często ograniczone. Porównanie z istniejącymi danymi referencyjnymi (personel, wierzyciele, zamówienia itp.) poprawia skuteczność rozpoznania.
Dane indeksowane można automatycznie zarejestrować i zatwierdzać oraz sprawdzać na różne sposoby. Treści nierozpoznane lub rozpoznane w niewystarczającym stopniu są uzupełniane lub poprawiane ręcznie. Pozyskane w ten sposób dane i obrazy (PDF, TIFF itp.) są dalej eksportowane do firmowego obiegu dokumentów.
